A Complete View of High Performance Systems
Raise of HPC
The need to execute complex and demanding problems at scale is more imminent than ever! The rise of big data and the requirements for just in time solutions made HPC a dominant research area of our era.
Building Blocks of HPC
Typical HPC systems have 3 main components:
- Compute
- Storage
- Network
HPC solutions can be deployed on Cloud, Edge, and On-Premises. Let’s dive deep into each component of the HPC System.
Compute
To build a high-performance computing architecture, compute servers are networked together into a cluster. There are two types of HPC systems: Homogeneous Systems and Hybrid Systems. Homogeneous systems only have CPUs while the hybrids have both GPUs and CPUs. In Hybrid systems, parallel processing done by multiple CPUs or GPUs and serial processing like running operating systems will be done by CPUs. As of now, 2/3rd of the supercomputers are hybrid machines because GPUs are more energy efficient, supports faster memory, execute millions of threads simultaneously.
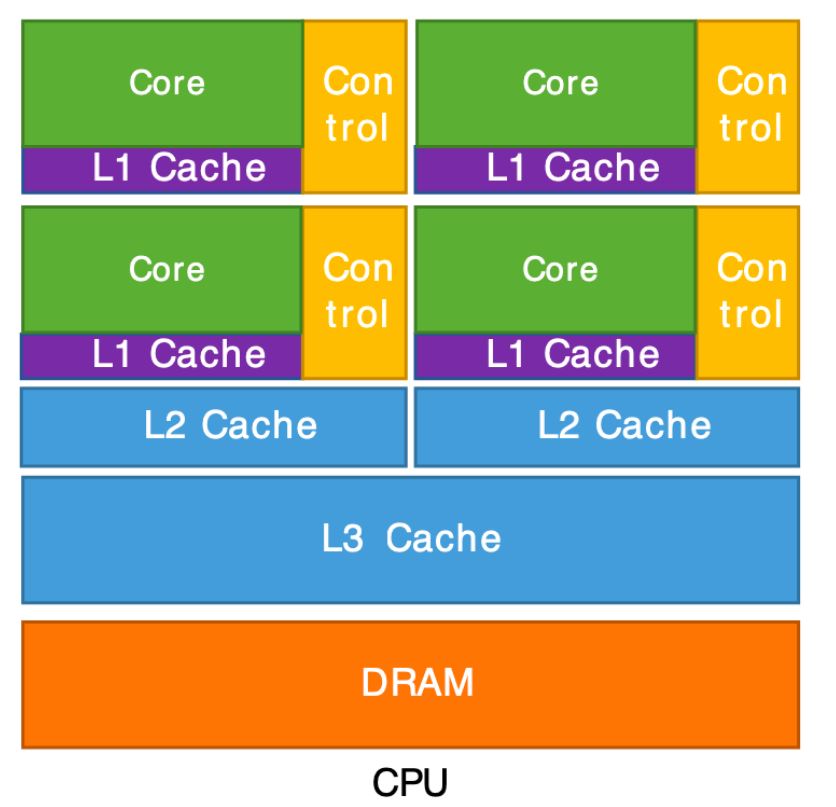
CPU
- CPUs are architected to handle wide variety of workloads such as complex branch prediction, input/output (I/O) operations, basic arithmetic, and logic.
- CPUs can deal with diverse set of instructions to manage all parts of the computer and run all kinds of computer programs.
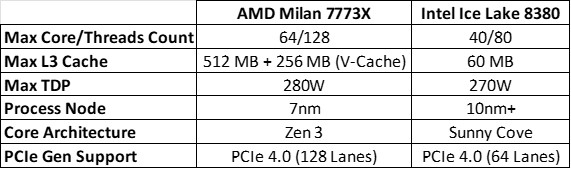
- AMD vs Intel
- For HPC needs, AMD ships AMD EPYC Processors (Ex: AMD Milan Series) and Intel ships Intel Xeon Scalable Processors (Ex: Intel Icelake Series)
- AMD adopted Chiplet like design for EPYC series which have several advantages over monolithic designs.
- Intel developed OneAPI, a HPC software suite optimized for its hardware. AMD is also have AOCC, AOCL software products which are optimized for their hardware.
- Here is the comparison between two flagship processors released in 2021.
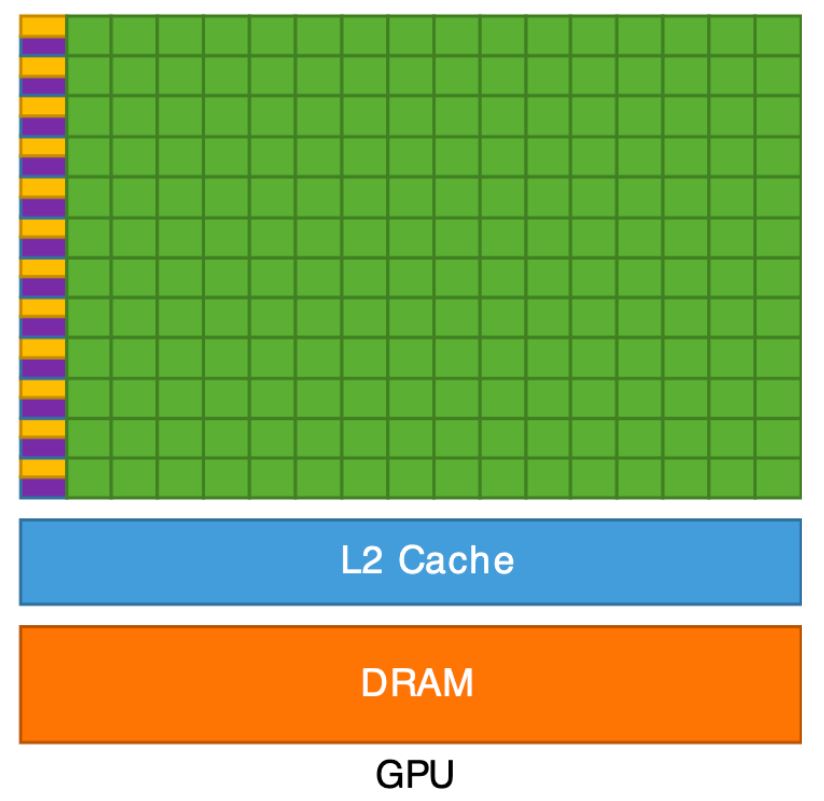
GPU
- GPUs are architected to deal with potentially large data streams in parallel.
- GPUs per-core caches relatively smaller than CPUs, but their memory bandwidth is extremely faster.
- CPU and GPU are two distinct types of processors. CPU is aimed at general purpose instruction streams, and GPU is aimed at bulk data handling. Hence, instructions vs data processing is what separates a CPU from a GPU.
- Due to parallel architecture and high-performance nature of GPUs, it offers computing speedups for certain workloads such as AI and ML.
- AMD vs NVIDIA
- For HPC needs, AMD ships AMD Instinct GPUs (Ex: MI200 series) and NVIDIA ships NVIDIA Ampere Series GPUs (Ex: A100 Series GPUs).
- The software stack consists of the compilers and math libraries in the ROCm stack from AMD for its own GPUs versus the CUDA stack from Nvidia for its own GPUs.
- Here is the comparison between two flagship processors released in 2021.

Storage
- In Scaling out HPC environment, there is a need for new storage systems to provide massive parallel IO to be able to scale out together with the compute.
- Traditional storage consists of various specialized hardware in datacenters such as firewall servers, storage servers, compute servers. Now a days the server’s software defines its role rather than custom hardware. The same server can also be a web server, a load balancer, a storage server, or a compute node - it all depends on the software You install on the server.
- To address the massive parallel IO requirements there were different file systems developed.
- Network File System (NFS)
- NFS is not the actual file system, but the protocol used between the clients and the servers with the data.
- NFS failed to serve the ever-changing needs of storage users today. Now a days almost all operating systems can access NFS version 3 storage
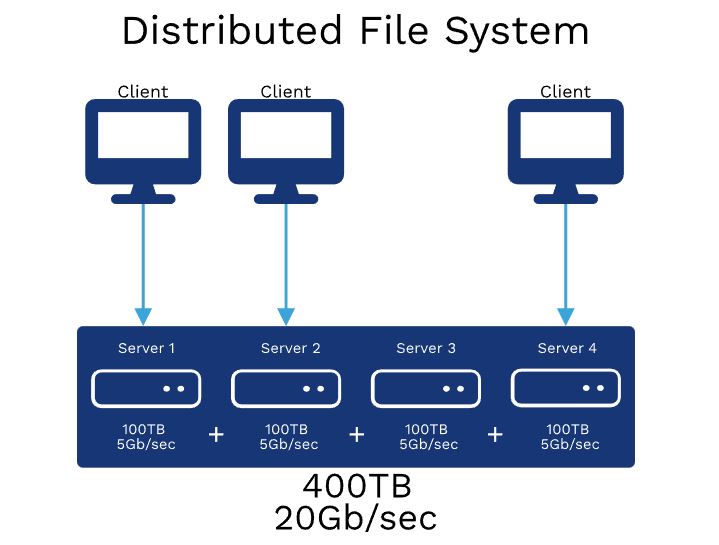
- Distributed File System (DFS)
- As the name suggests, is a file system that is distributed across multiple file servers or multiple locations. Its primary purpose is to reliably store files.
- DFS provides transparency data even if server or disk fails, allows data to be shared remotely.
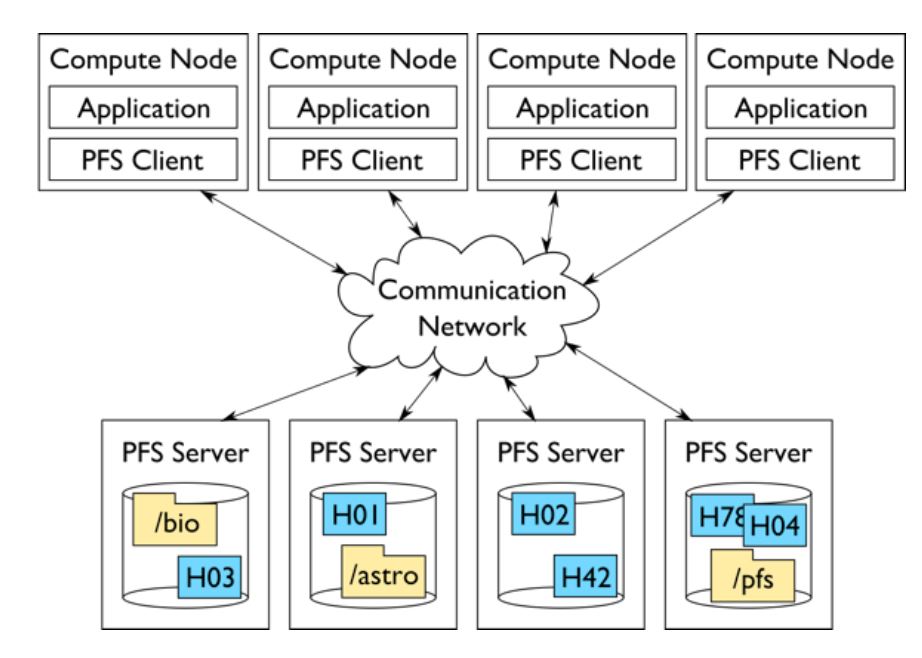
- Parallel File Systems (PFS)
- PFS has ability to do IO in parallel to multiple file servers, i.e a client can directly access several storage servers in parallel to take advantage of the aggregated bandwidth of multiple servers.
- Parallel file systems distribute data of a single object across multiple storage nodes.
- Popular parallel file systems are Lustre, Ceph, IBM Spectrum Scale, and BeeGFS.
- Scratch File Systems
- The scratch file systems are intended for temporary and intermediate files, so they are not backed up. For example, /tmp directory in Cluster.
- To satisfy these use cases, the technologies used in the storage solution could include SAS/SATA disks, SSDs, NVMe and any combination of these. The choice of storage solution would depend on performance, capacity, and cost.
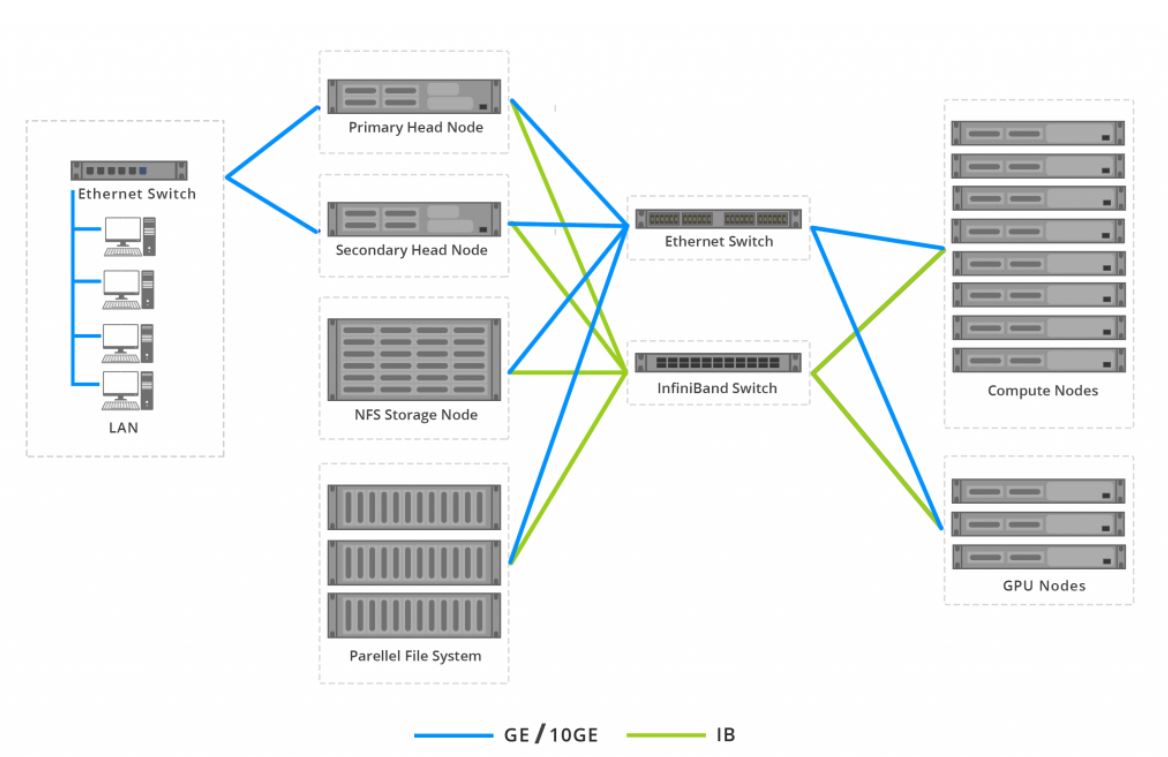
Network
- High Performance Computing (HPC) networking is very different to the internet or typical local area networks, both in terms of the hardware and the software involved.
- Software and Hardware layers in HPC typically need to provide more stringent guarantees for data delivery. Routing between nodes in a Cluster / Supercomputer.
-
The critical qualities of HPC networks are Low latency, Topology, Resilience, Load balance.
- Low Latency
- High performance computing (HPC) requires an extremely high-powered network with ultra-low latency to move large files between HPC nodes quickly. RDMA facilitates more direct and efficient data movement into and out of a server by implementing a transport protocol in the network interface card (NIC) located on each communicating device.
- Topology
- Good topology will have smaller diameter (max distance between 2 nodes), small nodal degree (max links connected to a node) and large bisection bandwidth (smallest bandwidth between half of the nodes to another half). A common network topology is a fat-tree.
- Resilience
- The resiliency of high-speed interconnect is fundamental to sustaining continuous execution of applications in any high-performance computing (HPC) environment. Job scheduling, application message exchanges, file system operations, and remote access functionalities rely on the continuous availability of a robust and fast network.
- Load Balance
- The most common HPC protocol is Infiniband to perform better across all possible paths as traffic is sent along the optimal path and load balance.
High Performance Interconnet : Creating efficient interconnect links between the servers and storage within your cluster can include many different types of technologies being transmitted over various distances. Ethernet, Omni-Path and InfiniBand are just three of the most commonly used within the world of HPC.
Administration Fabric : 1GbE is available on all platforms and suffices for deploying the software on a cluster, management, and monitoring of system health.
IPC and Storage Fabric : Typically, InfiniBand or Omni-Path is used as the high-performance fabric providing low latency and high bandwidth connectivity between compute platforms for IPC and access to the storage.
Software
- HPC cluster software is a suite of tools that are packaged together to make it easy to deploy, administer and maintain the HPC system. As with the hardware, the software is assembled in a modular manner. There are multiple choices for individual components (like resource manager, MPI, compilers etc.) and support for drivers based on the hardware selections.
- The cluster software packages allow the administrator to manage the entire HPC system as one unit.
HPC System Infrastructure
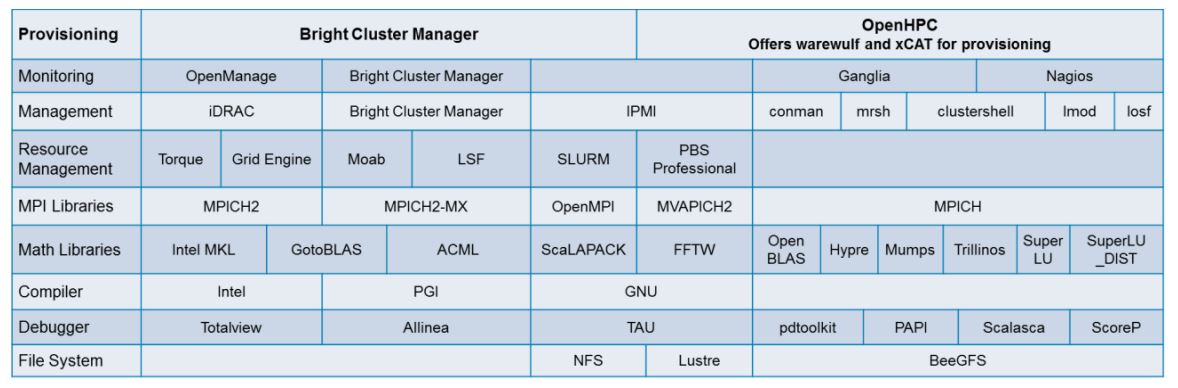
Cluster Provisioning Tools: There are mainly 2 Cluster management solutions for provisioning of cluster which are Bright Cluster Manager and OpenHPC.
- Bright Cluster Manager: This professional package allows complete control of the cluster software environment from a single pointed-click interface that does not require advanced systems-administration skills
- OpenHPC: This is freely available for open-source distribution mainly contributed by research institutions, supercomputing sites.
Cluster Monitoring Tools:
- Monitoring the cluster is critical task as losing one node can kill the entire application.
- HPC monitoring systems will have lot of data sources like, power supplies, storage or network devices, kernel events.
Resource Management:
- Resource management tools are in-charge of allocating resources on the HPC cluster for your job. It does not actually utilize the resources that it makes available.
- The term scheduling stands for the process of computing a schedule. This may be done by a queuing or planning based scheduler.
- A resource request contains two information fields: the number of requested resources and a duration for how long the resources are requested.
- A job consists of a resource request as above plus additional information about the associated application. Examples are information about the processing environment (e. g. MPI )
- A reservation is a resource request starting at a specified time for a given duration.
MPI, OpenMP and Math Libraries:
- OpenMP is a programming platform that allows one to parallelize code over a homogeneous shared memory system (e.g., a multi-core processor). For instance, one could parallelize a set of operations over a multi-core processor where the cores share memory between each other. This memory includes cache memory, RAM, hard disk memory.
- Open MPI (based on Message Passing Interface) is also a programming platform, but instead provides one the ability to parallelize code over a distributed system. For instance, it’s possible to parallelize an entire program over a network of computers, or nodes, which communicate over the same network. Since these nodes are essentially computers, they have their own memory layout and their own set of cores (see OpenMP description). Communication between nodes, when compared to shared memory systems, can be difficult and is usually expensive.
Math Libraries:
- Mathematics or numerical libraries are designed to be incorporated into user applications. They contain high-quality implementations of common tasks such as linear algebra solvers or fast Fourier transforms.
- Major libraries and interactive mathematical tools include BLAS, FFTW, LAPACK, MKL, LIBM, PETSc and ScaLAPACK.
Compilers:
- A Compiler translates this code into a binary file, which can be executed. Numerous compilers are available to provide a rich programming environment for scientific and technical computing.
- Well-known compilers are GNU, Intel oneAPI, NVIDIA HPC SDK, AOCC, LLVM.
Kernel: Kernel is the most important part of an Operating System. Whenever a system starts, the Kernel is the first program that is loaded after the bootloader because the Kernel must handle the rest of the thing of the system for the Operating System.
Firmware: Firmware is a specific class of computer software that provides the low-level control for a device’s specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems.
Device Drivers: A device driver is a computer program that operates or controls a particular type of device that is attached to a computer or automaton. A driver provides a software interface to hardware devices, enabling operating systems and other computer programs to access hardware functions without needing to know precise details about the hardware being used.